

![]()
Ein Information Broker für wiederverwendbare Lernmodule
Jodok
Batlogg, Dirk Feuerhelm, Bodo Pfannenschwarz
Universität Karlsruhe, Institut für Telematik, Forschungsgruppe Cooperation & Management
Geb. 20.20, Zirkel 2, 76128 Karlsruhe, Germany
© EURODL 1999
Abstract
Ausgehend von einem pädagogisch-didaktischem Modell werden die Anforderungen an ein verteiltes System zur Speicherung, Verwaltung und Bereitstellung von Lerneinheiten (Module) erarbeitet. Dabei wird gezeigt, wie mit Hilfe von standardisierten Metadaten und deren konsequente Verwendung Flexibilität in das Informationssystem eingebracht wird. Basierend auf diesen einführenden Grundlagen und Anforderungen wird grob auf die Architektur des Systems eingegangen. Nach einer kurzen Beschreibung des Frontends wird im zweiten Teil ein wesentlicher Teil des Informationssystems - der Information Broker - ausführlicher behandelt. Es wird auf dessen Design sowie auf konkrete Implementierungsaspekte eingegangen.
Key words: Tele-learning, Computer Based Training, Web Based Training, Metadata, Information Systems
Motivation
Die rasante Entwicklung der Informationstechnologie spiegelt sich in allen Lebenslagen wieder. Ob E-Mailabruf über mobile Kommunikationsgeräte oder rechnerunterstützte Produktion und Fertigung, alle Bereiche in denen die Computertechnologie Einzug hält, verlangen nach einfacher und intuitiver Bedienung. Dies widerspricht allerdings der steigenden Funktionalität und Komplexität solcher Systeme. Daher ist eine Unterstützung des Benutzers über Hilfe- oder Lernsysteme unerlässlich geworden.
Nicht nur die Beschreibung und Erklärung solcher Systeme, sondern auch das allgemeine Bestreben, das erlangte Wissen in digitale Form und somit für über den Computer zugreifbar umzuwandeln, lassen die Diskussion über Lehr- und Lernsystem in letzter Zeit aufblühen. Hinzu kommt, dass durch die rasante Entwicklung und Verbreitung des Internets und die immer günstiger werdenden Zugänge zum Internet das Verlangen, Wissen zeit- und ortsunabhängig zur Verfügung zu haben, erheblich begünstigt wird. Deshalb findet man neben den schon länger existierenden CBT (Computer Based Training)-Systemen zunehmend zahlreiche webbasierte, multimediale Lehr- und Lernsysteme, sogenannte WBT (Web Based Training)-Systeme auf dem stetig wachsendem Markt der Bildungssysteme.
Eine Zielsetzung der Universität ist es, Lernmaterialien in einer virtuellen Hochschule zur Verfügung zu stellen und diese mit anderen Hochschulen auszutauschen. Am Institut für Telematik der Universität Karlsruhe wird versucht, dieses Ziel mit einem webbasierten, multimedialen Lehr- und Lernsystem, dem Nexus-System, zu entwickeln und an einen europaweit verteilten Datenbestand von telematikspezifischen Lernmaterialen und -kursen anzugliedern.
Szenario
Im folgenden sollen Einsatzszenarien eines Lehr- und Lernsystems näher betrachtet und Anforderungen an das System herausgestellt werden.
Einsatzmöglichkeiten
Universität/Schule
Da die Universitäten schon sehr früh über eine entsprechende Infrastruktur zur Nutzung des Internets verfügten, wurden hier bereits Ende der achtziger Jahre auf dem Gebiet der Lehr- und Lernsysteme geforscht. Da die Hochschulen neben der Forschung auch der Lehre verpflichtet sind, bot sich der Einsatz solcher Lehr- und Lernsysteme im Lehrbetrieb an.
Erst nach der flächendeckende Einführung von breitbandigen Netzverbindungen und entsprechenden leistungsfähigen multimediatauglichen Computern in den Universitäten ist ein regulärer Betrieb eines solchen Systems in der Lehre denkbar. Den Studenten wird neben Textbüchern und Vorlesungsskripten der klassischen Lehre ein Lehr- und Lernsystem zur Verfügung gestellt. Dieses System muss somit über frei zugängliche Rechner der Universität verfügbar gemacht werden. Der Student kann dann die multimedialen Lehrinhalte unabhängig von der Vorlesungszeiten aufrufen und bearbeiten. Besitzt der Student zusätzlich noch einen breitbandigen Netzanschluß in seiner Wohnung, so kann er die Lehrinhalte auch von zu Hause abrufen.
Die angebotenen Lehrinhalte beziehen sich in erster Linie auf den Studiengang und sind somit als Basis- und Spezialwissen einzuordnen. Trotzdem sollte auch versucht werden, diese Inhalte über Universitätsgrenzen hinaus austauschbar und dadurch wiederverwendbar zu machen. Ein kontinuierlicher Einsatz von Lehr- und Lernsystemen in der Universität wird derzeit noch durch fehlende, multimedial aufbereitete Lehrinhalte verhindert.
Ein ähnliches Einsatzszenario findet sich an den Schulen wieder. Allerdings hinkt hier die Modernisierung der entsprechenden Infrastruktur zur Nutzung des Internets und multimedialen Anwendungen dem neuestem Stand der Technik hinterher. Auch der Mangel an pädagogisch angemessenen, multimedial aufbereiteten Lehrinhalten lässt eine flächendeckende permanente Nutzung dieser Technologien an Schulen erst in ein paar Jahren zu.
Heimbereich
Ähnlich wie die Schulen verfügt der Heimanwender in der Regel nicht über die neueste Technologie zur Nutzung multimedialer webbasierter Lehr- und Lernsysteme. Während bei Universitäten und Schulen die öffentliche Hand zur Finanzierung dieser zukunftsweisenden Technologien beiträgt, ist der Heimanwender in der Regel auf sich allein gestellt. Die nicht breitbandigen und teuren Netzanschlüsse erlauben es dem Heimanwender nicht, in einen permanenten Genuß von Multimedia zu kommen. Von daher beschränkt sich der Einsatz von Lehr- und Lernsystemen derzeit auf den Vertriebs per CD-Rom oder auf wenig oder gar nicht multimedial aufbereitete Lehrinhalte. Diese wiederum stehen dem Heimanwender zwischenzeitlich in großer Auswahl zur Verfügung. Durch den weltweiten Zugang über das Internet hat der Heimanwender auf fast alle Themengebiete Zugriff.
Industrie
Der Einsatz von webbasierten multimedialen Lehr- und Lernsystemen in der Industrie stellt durch das Vorhandensein von interner Netzinfrastruktur und leistungsfähiger Rechner kein Problem mehr dar. Hier ist auch der Einsatz eines solchen Systems anzusiedeln. Zur Weiter- und Fortbildung der Mitarbeiter werden über das Intranet der Firmen entsprechende Weiterbildungskurse und Lehrmaterialien angeboten. Diese Fortbildungsmaßnahmen werden dann während der Arbeitszeit wahrgenommen. Es liegt also im Verantwortungsbereich des Mitarbeiters, seine Arbeitszeit so zu organisieren, dass entsprechende Kurse durchgearbeitet oder Lehrinhalte angeschaut werden können. Die Inhalte beziehen sich zumeist auf die Produkte und Dienstleistungen des einzelnen Betriebs und sind somit sehr speziell gehalten. Allerdings können diese Lehrinhalte, sofern sie sich nur auf die Beschreibung von Produkten beziehen, direkt an den Kunden weitergegeben werden.
Verteilte Plattform
Um den oben beschriebene Einsatzszenarien gerecht zu werden, wird hierfür eine verteilte Plattform entwickelt. Die verteilte Plattform soll den Knotenpunkt zwischen den Lernumgebungen und den Autorenumgebungen darstellen (vgl. Abbildung 1). Die Plattform wird im folgenden "Nexus" genannt. Im Hierdurch wird die Ortsunabhängigkeit des Lernenden unterstützt, da dieser nun von jedem Rechner mit Internetanschluss aus über die Plattform auf jegliche im System abgelegte und vom Lernenden bereits bearbeitete Kurse zugreifen kann. Die Verteilung und Dezentralisierung einer solchen Plattform erhöht auch die Verfügbarkeit der Lernmaterialien und unterstützt die Zeitunabhängigkeit des Lernens.
Den Autoren bietet das Nexus-System neben der erhöhten Verfügbarkeit und Ortsunabhängigkeit Zugriff auf sämtliche bestehende Lehrmaterialien. Diese können dann dazu benutzen, eigene Kurse zu ergänzen oder neue damit aufzubauen. Die Wiederverwendbarkeit von Lehrmaterialien wird durch eine verteilte Plattform bestens unterstützt.
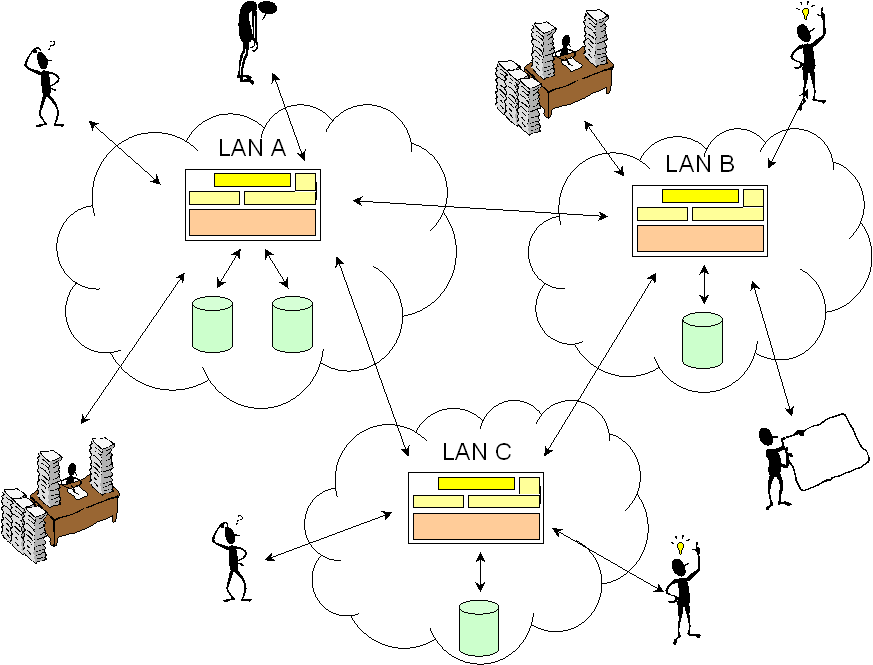
Abbildung 1: Zusammenspiel zwischen Lernendem, Autor und verteilter Plattform
Die Nexus Plattform
Konzeption / Pädagogische Aspekte
Neben dem technischen Entwurf entscheiden die didaktischen Konzepte maßgeblich über Erfolg und Misserfolg eines Lernsystems. Bei der Entwicklung wurden daher auch diese Aspekte gleichberechtigt zu den technischen Herausforderungen berücksichtigt. Im folgenden sollen die wichtigsten Konzepte kurz vorgestellt werden [1], [2]:
Einbettung in eine integrierte Lernumgebung
Unter einer integrierten Lernumgebung versteht man eine Sammlung von Unterrichtsmethoden und -techniken sowie von Lehrmaterialien und Medien, die weitestgehend aufeinander abgestimmt sind. In diesem Zusammenhang spielten bei der Entwicklung des System-Frontends [3] insbesondere die Aspekte Lernort, Medienintegration und Interaktionsebene eine entscheidende Rolle.
Das Nexus-Frontend wurde in bezug auf den Lernort so entwickelt, dass das System sowohl im Rahmen einer Präsenzschulung im Schulungsraum als auch in der Telesituation am Lernarbeitsplatz des Lernenden eingesetzt werden kann. Beide Einsatzszenarien stellen dabei unterschiedliche Anforderungen an ein Lernsystem. Im Rahmen einer Präsenzschulung kann der Lehrende selbst entscheiden, in welchem Umfang er das System einsetzen möchte. Sowohl ein gezielter Einsatz von Lernbausteinen als auch vollständige Präsentationen sind möglich. Das Nexus-Frontend ist komplett HTML-basiert und passt die Darstellung der Inhalte automatisch an die verwendete Bildschirmauflösung an. Dies erlaubt die problemlose Verwendung unterschiedlichster Präsentationsmedien.
In der Telesituation bietet das Nexus-Frontend dem Lernenden in der Hauptsache die Möglichkeit des zeit- und ortsunabhängigen Lernens. Zudem bekommt der Lernende mit einem solchen Lernsystem die Möglichkeit, das Lerntempo selbst zu bestimmen und durch die beliebige Wiederholbarkeit das erlangte Wissen zu festigen. Durch interaktive Lernbausteine, wie Animationen und Simulationen, wird das explorative Lernen gefördert und der Lernende bekommt die Möglichkeit, das erworbene Wissen anzuwenden oder zu vertiefen [4], [5].
Wiederverwendbarkeit von Lerninhalten
Zur Sicherstellung der Wiederverwendbarkeit von Lerninhalten wurde bei der Entwicklung auf bewährte Konzepte der Softwaretechnik zurückgegriffen.
Eines der wesentlichen Merkmale ist dabei der modulare Aufbau aus wiederverwendbaren Lernmodulen. Ein solches Lernmodul besteht aus einer oder mehreren HTML-Seiten mit Texten, Bildern, Animationen etc. und lässt sich als thematisch abgeschlossene Lerneinheit definieren. Da das System als Hypermediasystem konzipiert ist, sind die einzelnen Seiten eines Lernmoduls über Hyperlinks miteinander verknüpft. Nach dem selben Prinzip können auch feste Querbezüge zwischen Lernmodulen hergestellt werden (siehe Abbildung 2).
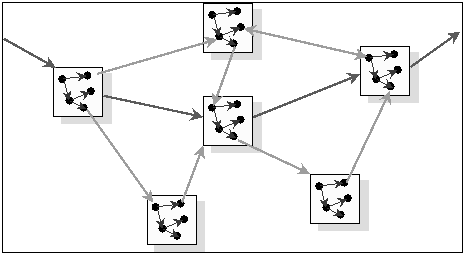
Abbildung 2: Lineare
Verkettung von Lernmodulen durch eine Guided Tour
(dunkler Pfeil - Guided Tour, helle und dünne Pfeile - traditionelle Links)
Konfigurierbarkeit für unterschiedliche Zielgruppen und/oder Lehrkontexte
Legt man bei der Gestaltung des Lernsystems Wert auf die Wiederverwendbarkeit und die Konfigurierbarkeit für unterschiedliche Zielgruppen und Lehrkontexte, erweisen sich statische, vom Lernmodulautor fest vorgegebene Querverweise als problematisch. Aus diesem Grund wurde beim Nexus-System das Guided-Tour-Konzept eingeführt, das die lehrkontextspezifische Navigation durch die Lernmodule von den eigentlichen Lerninhalten entkoppelt [6]. Eine Guided Tour läßt sich als lineare Verkettung von Lernmodulen unter einem ganz bestimmten Blickwinkel definieren. Sie wird im System unabhängig von den eigentlichen Lernmodulen erstellt und verwaltet. Eine eigene Guided-Tour-Steuerung gestattet es dem Benutzer, die einzelnen Tourschritte direkt anzuspringen. Wie man Abbildung 2 entnehmen kann, bleiben dabei die traditionellen Hyperlinks in Form von Querbezügen zwischen den Lernmodulen weiterhin erhalten. Sie beschreiben jedoch ausschließlich thematisch begründete Zusammenhänge zwischen den Lerninhalten. Dem Lernenden bleibt es ungenommen, zu einem beliebigen Zeitpunkt den Tourpfad zu verlassen und einem eigenen Pfad zu folgen. Da sich beliebige Web-Seiten in die Guided Tour einbinden lassen, kann der Lernende von hier aus beliebigen Links im Internet folgen. Über einen Knopf der Guided-Tour-Steuerung kann er zu jedem Zeitpunkt zur Tour zurückkehren und somit den Lost-in-Hyperspace-Effekt vermeiden [5].
Um die Wiederverwendbarkeit von Modulen sicherzustellen, dürfen diese keine kontextspezifischen Informationen in Form von Einleitungen, Überleitungen, Zusammenfassungen, direkte Bezüge zu einer bestimmten Lehrveranstaltung oder informelle Kommentare des Dozenten enthalten. Aus diesem Grund wurden im Nexus-System für derartige Metainformationen sogenannte Metamodule eingeführt, die diese Informationen aufnehmen können. Metamodule unterscheiden sich von herkömmlichen Lernmodulen darin, dass sie genau einer Guided Tour zugeordnet sind und nur in diesem Zusammenhang einen Sinn ergeben. Abbildung 3 zeigt den schematischen Aufbau einer mit Metamodulen ausgestatteten Guided Tour.

Abbildung 3: Beispiel für eine Guided Tour mit Metamodulen
Technik / Architektur
Eine zentrale Forderung an das System ist die problemlose Pflege und Erweiterung von Lerninhalten, d.h., Lerninhalte sollen flexibel in das Lernsystem eingebracht, modifiziert und entnommen werden können. Weiterhin soll das Basissystem plattformunabhängig eingesetzt werden.
Um eine hohe Wiederverwendbarkeit zu garantieren, müssen sämtliche Module in einem großen Pool von gespeicherten Lerninhalten schnell und einfach lokalisiert werden können. Die Granularität der gesuchten Module ist sehr unterschiedlich: komplette Kurse, verschiedene Abbildungen und Diagramme, Teile von Kursen um einen neuen Kurs zu konstruieren. Um die gespeicherten Daten durchsuchen zu können, wird ein "Content Directory System" (CDS) benötigt. Das CDS greift auf einen vordefinierten Satz von Metadaten zurück. Dadurch ist es möglich, wesentlich genauere und detailliertere Suchanfragen zu stellen, als mit einer konventionellen Stichwort-Anfrage. Die Anforderungen der verschiedenen Benutzer wie Lernende, Lehrende oder Autoren an das CDS sind sehr verschieden, so dass das CDS adaptives Verhalten zeigen muss.
Außerdem wird ein System benötigt, das als Plattform für die verschiedenen Anwendungen wie Arbeitsumgebung der Autoren oder das Frontend der Lernenden dient. Dieses System muss die verteilte Architektur des Gesamtsystems verschatten und abstrahieren. Durch die Hilfe von Middlewarekomponenten werden diese verschiedenen Dienste verbunden und bilden den "Content Management Service" (CMAS).
Schlussendlich muss ein ansprechendes webbasiertes Frontend für die Lernenden bereitgestellt werden. Das Frontend muss nahtlos in das Gesamtsystem eingebunden werden und wird im folgenden nur kurz erwähnt, weitere Informationen finden sich in [3]. Das System bildet somit eine klassische "Three-Tier-Architektur" bestehend aus Frontend-Applikation, Middleware (CMAS), und der Datenhaltung (vgl. Abbildung 4). In den folgenden Abschnitten soll kurz auf das Nexus-Frontend und schließlich ausführlicher auf die serverseitigen Komponenten, im folgenden "Information Broker" genannt, eingegangen werden.
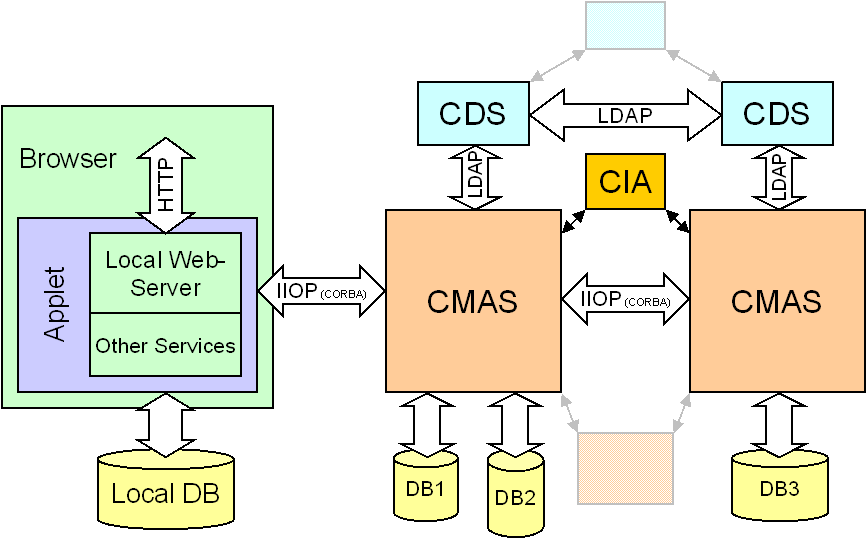
Abbildung 4: Architektur des Nexus-Systems
Das Nexus-Frontend
Die Ablaufumgebung präsentiert sich dem Benutzer des Lernsystems, wie in Abbildung 5 dargestellt, in einem Webbrowser als in HTML realisierte Bedienoberfläche. Die WWW-Seite wurde in fünf HTML-Frames aufgeteilt.
Abbildung 5: Oberfläche des Nexus-Frontends
Kopfleiste
Die Kopfleiste enthält Verweise, welche den Lernenden zur Startseite
des Lernsystems, zur Homepage des Lernsystembetreibers oder zu Hilfeseiten führt.
Lernmodulbereich
In diesem Bereich werden bei gestarteter Guided Tour die Lernmodule und Metamodule
angezeigt. Wenn das System startet und noch keine Tour aktiv ist, enthält der
Lernmodulbereich die Startseite des Lernsystems.
Tourtitelbereich
Hier wird der Titel der aktiven Tour angezeigt.
Metainformationsbereich
Hier bietet sich dem Autor die M öglichkeit, den Lernenden gezielt auf
bestimmte Teilbereiche eines Lernmoduls oder einer Lernmodulseite hinzuweisen.
Lernsystemsteuerung
Die im Steuerungsbereich untergebrachte Steuerungsleiste wird zur Navigation
zwischen den Lernmodulen einer Guided Tour sowie zum Aufrufen der Tour übersicht
verwendet.
Nexus-Information Broker
Anforderungen
Hauptaufgabe des Information Brokers innerhalb des Nexus-Systems ist die Verwaltung von Informationen über die in das System eingebrachten Inhalte. Die zwei wichtigsten Aspekte sind dabei einerseits die Erfassung von Metadaten zu den Inhaltsobjekten, um diese geeignet zu attributieren und charakterisieren, andererseits ein Mechanismus zur persistenten Ablage der Metadatensätze und zur Unterstützung von Suchanfragen über diese abgelegten Daten.
Da im Zugriffsprofil auf diese Daten die Anzahl der Suchanfragen deutlich höher liegen dürfte als die Menge der Einbring-Transaktionen, ist darauf zu achten, dass Suchzugriffe möglichst performant verarbeitet werden können, auf Kosten der Performance von Einbringungsoperationen. Dabei kann – auch hinsichtlich des verteilten Charakters des Systems – die Forderung nach Konsistenz und Atomizität abgeschwächt werden.
Diese Eigenschaften entsprechen im Wesentlichen den Anforderungen an einen Verzeichnisdienst, so dass bei der Realisierung des Information Brokers auf bekannte und erprobte Methoden und Mechanismen zurückgegriffen werden kann.
Realisierung
Die Gestaltung der Metadatensatzstruktur ist in mehrerlei Hinsicht richtungsweisend für die Verwendbarkeit der zugrundeliegenden Inhaltsobjekte. Zum einen muss die Möglichkeit gegeben sein, Inhaltsobjekte verschiedener Granularitätsstufen zu unterstützen, damit sowohl große, monolithische Objekte wie beispielsweise komplette Kurse, als auch kleinere Items wie Schaubilder oder Videosequenzen gezielt auffindbar und damit wiederverwendbar sind.
Die Wiederverwendbarkeit ist dabei aus der Sicht des Autors, der bei der Neuerstellung eines Kurses einen Überblick über für ihn nutzbare Objekte wünscht, wie auch aus der Sicht eines Lernenden, der sich dafür interessiert, welche Kurse mit welchen Eigenschaften zu einem bestimmten Themengebiet zur Verfügung stehen, zu betrachten. Weiterhin sollte der Metadatensatz so ausführlich wie möglich sein, damit differenzierte Suchanfragen unterstützt werden können, andererseits aber auch klein gehalten werden, damit Autoren nicht durch überlange auszufüllende Metadatenformulare abgeschreckt werden und bestehende Inhalte mit wenig Aufwand attributiert und ins System eingebracht werden können. Der dritte Aspekt ist die Wiederverwendbarkeit über Systemgrenzen hinaus. Bislang existierende Lernsysteme bedienen sich einer proprietäre Metadatenstruktur, somit ist die Nutzung an das System gebunden.
Das IMS-Projekt (Instructional Management System), ein internationales Projekt unter der Leitung von EDUCAUSE [7], einem Konsortium von Colleges, Universitäten und Industriepartnern, hat sich bereits einigen Aspekten dieser Problematik angenommen. Als Teilergebnis wurde Ende August 1999 die Spezifikation eines Satzes von Metadaten für Lernressourcen veröffentlicht [8]. Das Hauptaugenmerk liegt hierbei auf den folgenden Bereichen:
herkömmliche Dokumentenbeschreibungsattribute wie Titel, Autor, Beschreibung etc. Informationen über die Meta-Metadaten, beispielsweise Zeitpunkt und Ersteller des Metadatensatzes Lehrtechnische Informationen wie Lernkontext oder Schwierigkeitslevel technische Eigenschaften wie Software- oder Betriebssystemanforderungen rechtliche Aspekte wie Copyrighteinschränkungen oder Verwertungstarife taxonomische Einordnung in einen Themenbaum
Die führenden Hersteller von Lernsystemen reagierten darauf mit Zusagen, ihre Produkte IMS-konform umsetzen zu wollen [9]. Die Spezifikation wurde der IEEE als Proposal zur internationalen Standardisierung vorgelegt. Sowohl die IMS- als auch die IEEE-Dokumente enthalten jedoch keine Details zur Implementierung der Metadaten wie Architektur, Datenablage oder Programmiersprache. Ebenso ist eine individuelle Erweiterbarkeit der Datenstrukturen vorgesehen, lediglich eine Kernmenge von Attributen muss gegeben sein.
Als Austauschformat für die im Nexus System anfallenden Metadaten wurde XML (eXtensible Markup Language) gewählt. XML erfreut sich weltweit zunehmender Akzeptanz und Verbreitung als allgemeiner, frei definierbarer Strukturdefinitionssprache und bietet sich daher zum Einsatz bei der Festlegung der Datenarchitektur an. Zudem befinden sich zahlreiche Hilfsmittel wie XML-Editoren oder XML-Server auf dem Markt und in Entwicklung, so dass externe Werkzeuge problemlos in das Nexus System eingebunden werden können. Der Ansatz verschiedener Granularitätsstufen kann dabei mittels unterschiedlicher DTDs (Document Type Definition) realisiert werden, wobei gemeinsam auftretende Attribute in externen Entities zentral vereinbart werden können. Die IMS-Spezifikation beinhaltet bereits zwei DTDs, einerseits eine XML-Umsetzung der dem Standard genügenden Attributskernmenge, andererseits eine Umsetzung der gesamten spezifizierten Eigenschaften.
Die Anforderungen des Nexus Information Brokers bezüglich der Metadatenablage und der Suchanfragenmöglichkeit entsprechen wie angesprochen weitgehend denen eines Verzeichnisdienstsystems. Aus diesem Grund bietet sich die Verwendung von LDAP (Lightweight Directory Access Protocol) als Zugriffsprotokoll und eines LDAP-Servers zur Datenablage an. LDAP basiert auf X.500, einer ISO/OSI-Spezifikation für Verzeichnisdienste, die jedoch für viele Zwecke zu komplex ist, um effizient zum Einsatz zu kommen. Daher wurde LDAP als 90/10-Lösung entwickelt, d.h. 90% der Funktionalität von X.500 bei 10% der Komplexität. Zudem bietet LDAP den Vorteil, durch seine weite Verbreitung und Akzeptanz bereits Implementierungen im Open Source-Bereich vorweisen zu können. Die Verwendung solcher Software steht im Sinne des Open Courseware-Gedankens, welcher beim Nexus System verfolgt wird. LDAP ist zum Einsatz in einem verteilten System per se geeignet, da Verzeichnisdienste in der Regel nicht als atomare Systeme vorliegen. Aspekte wie automatische Replikation und Distribution von Daten in einer verteilten Umgebung und hierarchische Strukturierung des gesamten Datenbestandes werden bereits durch die Spezifikation abgedeckt.
Implementierungsaspekte
Als LDAP-Server kommt die Programmsuite des Open-Source-Projektes OpenLDAP zum Einsatz, welches von der OpenLDAP-Foundation koordiniert wird [10]. Beim derzeit in der Entwicklung und im Testbetrieb befindlichen Prototypen wird eine einzelne Instanz der Standalone-Ausführung des Servers, slapd, verwendet, als Betriebssystem kommt Linux zum Einsatz. Für den Übergang zum verteilten Betrieb steht im OpenLDAP-Programmpaket das Aktualisierungs- und Replikationstool slurpd zur Verfügung. Dieses sorgt – ähnlich wie die Mechanismen beim Domain Name Service im Internet – für eine automatische Verbreitung neu eintreffender Daten, wobei als Protokoll wiederum LDAP zur Anwendung kommt.
Die Datenhaltung des LDAP-Servers basiert auf der GDBM-Filesystemdatenbankbibliothek (GNU Data Base Manager) die unter Unix weit verbreitet ist. Hierbei erfolgt eine Umsetzung der vereinbarten LDAP-Objektklassenstruktur in multiple indexierte Einzeldateien, um einen performanten Zugriff zu gewährleisten.
Für jede im IMS Metadatenschema auftretende Basisklasse, also für jede vereinbarten XML-DTD, wird beim LDAP-Server eine entsprechende Objektklasse definiert und hinterlegt. Da die Struktur von LDAP-Objektklassen, wie in RFC2251 [11] definiert, keine direkte Schachtelung von Attributen vorsieht, bei XML-DTDs jedoch die Verschachtelung zur Strukturierung des Datensatzes dient, wird eine Abbildungsvorschrift vereinbart, um eine Transformation des DTDs in die flache LDAP-Objektklassenstruktur durchführen zu können.
Das DN (Distinguished Name)-Attribut, welches zur Identifikation der LDAP-Datensätze dient, und im LDAP-Verzeichnisbaum einmalig zu sein hat, wird hierbei aus dem General-Identifier-Attribut der IMS-Metadaten, welches zum Core-Schema gehört und daher stets gegeben ist, übernommen. Das äußerste XML-Schachtelungstag bestimmt den DTD-Typ und damit die Objektklasse. Ein weiteres Merkmal der IMS-XML-Metadatenstruktur ist, dass Werte ausschliesslich als Blattknoten im DOM (Document Object Model)-Baum auftreten. Somit ist ihre Einordnung in die Dokumentenstruktur durch den Pfad von der Baumwurzel zum Blattknoten eindeutig beschreibbar. Der entsprechende Attributsname in der LDAP-Objektklasse wird duch Konkatenierung der XML-Tags entlang des Pfades gebildet.
Ein weiteres Problem ergibt sich bei der Transformation von XML-Attributen. Diese können – im Gegensatz zu den oben behandelten XML-Werten – auch ausserhalb von Blattknoten auftreten und ihr Geltungsbereich erstreckt sich über den gesamten angeknüpften Subtree. Um diesen Sachverhalt in der Objektklassenstruktur nachbilden zu können, werden für jeden gespeicherten Wert sämtliche im Baum oberhalb liegenden und damit relevanten Attribute zusammen mit dem Wert selbst als LDAP-Attributswert abgelegt. Dies bedeutet zwar eine redundante Speicherung, ermöglicht jedoch einen schnellen Suchzugriff auf die abgelegten Informationen.
Die mögliche Komplexität von Suchanfragen geht weit über die derzeit im Internet üblichen Schlüsselwortsuchen hinaus. Ein Suchauftrag wird mittels eines LDAP-Filterausdrucks gemäß RFC2254 [12] formuliert, dies kann entweder direkt oder mit Hilfe des implementierten Java API erfolgen. Dieses unterstützt den Benutzer bei der Zusammenstellung seiner Suchparameter, indem es ihm die möglichen Suchattribute in Baumform zugänglich und selektierbar macht. Problematisch bei der Suche sind Suchzugriffe mit numerischen Vergleichen, da bedingt durch die Ablagestruktur der Inhalte diese nur als Strings gespeichert werden können. Numerische Vergleiche lassen sich daher einerseits durch Nachselektion nach Auswertung des Filterausdrucks realisieren, oder aber durch explizite und damit redundante Ablage des numerischen Wertes unter Ausschluss der zugehörigen XML-Attributswerte.
Der Zugriff auf den Information Broker durch andere Komponenten des Nexus Systems wird durch ein Java API realisiert, das nach aussen die Grundfunktionalität der Verzeichnisdienstkomponente anbietet, also eine insert-Funktion, eine delete-Funktion, eine Suchfunktion und eine retrieval-Möglichkeit. Die Einbringungsfunktion verarbeitet dabei als Eingabeparameter wahlweise den Metadatensatz als rohes XML-Dokument oder als expliziten DOM-Tree. Als XML-Parser kommt das von IBM erstellte Java-Package xml4j zum Einsatz [13], welches als Open Source Software verfügbar ist. Die Abwicklung der Kommunikation mit dem LDAP-Server wird mittels JNDI-Klassen (Java Naming and Directory Interface) realisiert, hierbei handelt es sich um ein offizielles Java Standard Extention Package von Sun.
References
- Arzberger, H.; Brehm, K.-H.: Computerunterstützte Lernumgebungen. München: Publicis MCD Verlag, 1994
- Petersen, K.: Design eines Courseware-Entwicklungssystems für den computerunterstützten universitären Unterricht, Verlag Peter Lang GmbH 1996
- Abeck, S.; Batlogg, J.; Feuerhelm, D.; Pracht, D.: "Companion" – eine multimediale, webbasierte Lehr- und Lernumgebung; APS99, Jena 1999
- Eberleh, E.; Oberquelle; H.; Oppermann, R.: Einführung in die Software-Ergonomie. Berlin: Walter de Gruyter, 1994
- Edwards, E.; Hardman, L.: ‚Lost in Hyperspace‘: Cognitive mapping and navigation in a hypertext environment. In: R. McAleese (ed.): Hypertext: Theoriy into practice. London: Intellect Limited; Norwood, N.J.: Ablex Publishing Corporation, 1989
- Kuhlen, R.: Hypertext – Ein nicht-lineares Medium zwischen Buch und Wissensbank. Berlin, Heidelberg: Springer, 1991
- EDUCAUSE, http://www.educause.edu
- IMS Metadata Specification, http://www.imsproject.org/metadata
- IMS Press Release, http://www.imsproject.org/pressRelease/pr990820.html
- The Open LDAP Project, http://www.openldap.org
- RFC2251, z.B. RFC-Archiv http://afs.wu-wien.ac.at/manuals/rfc/rfc2251.txt
- RFC2254, z.B. RFC-Archiv http://afs.wu-wien.ac.at/manuals/rfc/rfc2254.txt
- Xml4j – ein XML-Parser für Java, http://www.alphaworks.ibm.com